

图片来源:unsplash
撰文|王昱
审校|不周
我们已经离不开AI了——更确切地说,是越来越离不开大模型。
各大公司发布新模型的速度也越来越快,今年8月的GPT-5,上个月的Gemini 3,不断更新的千问、豆包等等。“前端已死”的论调反复出现,越来越多的人尝试用智能体(agent)改善自己的工作流,大模型炒股也吸引了一大波注意,还有人在讨论AI投资热潮究竟包含多少泡沫。这些新闻令人目不暇接,越关注AI的人,可能越难意识到DeepSeek-R1这个划时代的开源模型,竟然是今年发布的。
纵使有了这么多进展,大语言模型(LLM)依然是一个黑箱。如果你在本地部署过参数量较小的模型,可能很难想象这些“智障”和集群服务器上运行的巨无霸模型竟然共享几乎相同的架构。随着模型参数量不断增大,贴近、甚至超越大部分人类的智能突然涌现出来——它们甚至可以达到国际数学奥赛金牌的水平。模型究竟是如何变得这么聪明的?大模型中的参数太多、连接太多,我们很难看懂它们究竟是怎么得出答案的。
思维链(CoT)也许能让我们窥探模型的思想,但它本身也黑盒模型输出的一部分。思维链对“人类理解模型输出的推理过程”有帮助,但对“理解模型内部机制(为什么它能推理)”几乎没有帮助。换句话说,思维链提升的是“输出的可解释性”(output interpretability),但并不能提升“模型内部机制的可解释性”(mechanistic interpretability)。

这并不是计算机科学家期待的内部机制可解释性。图片来源于网络
虽然GPT-5早已发布,但最近OpenAI发布的一篇论文表示,他们甚至连GPT-2的内部机制都没能完全理解。
稀疏模型
以往的研究者为了寻找模型内部的运行机制,最大的困难往往是模型内部纷繁复杂的连接。在传统的神经网络中,神经网络中每一层的每个神经元,往往都与下一层的每个神经元相连。哪怕只是执行一个非常简单、确定性极高的任务,也会涉及多个神经元的协同工作,让研究人员弄不清楚模型在推理时究竟发生了什么。
而OpenAI改变了研究思路,他们不是在传统的模型中寻找可解释性,而是对模型进行修改,尝试提高模型的可解释性。为此,他们用到了稀疏模型。在研究中,他们采用了与GPT-2等现有语言模型非常相似的架构,但做了一个小修改:他们强制模型的绝大部分权重为零。这导致模型神经元之间的连接减少,从而更容易解释。
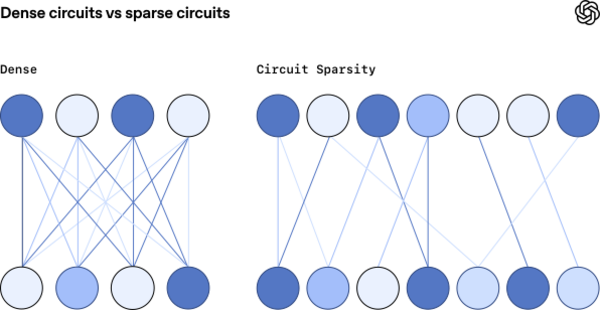
在常规的密集神经网络中,每个神经元都与下一层的每个神经元相连。而在稀疏模型中,每个神经元只与下一层的几个神经元相连。OpenAI希望这能让神经元以及整个网络更容易理解。图片来源:OpenAI
在用稀疏模型训练好模型后,他们用一些任务来测试模型,并尝试寻找模型推理时的内在机制。
其中一项任务是,让稀疏模型输出一段Python代码。在Python代码中,字符串必须用引号标注,并且字符串开头的引号如果是单引号,结束的引号也必须是单引号;开头是双引号,结束也必须是双引号。比如”Python”和’Python’都是合规的字符串,但”Python’是错误的。
结果,OpenAI在稀疏模型中找到了一条特定的回路。在这条回路中所有的事情都只和判断字符串前后的引号相关。比如,其中的一个神经元专门负责检测字符是否是引号,另一个神经元专门负责区分单引号,还有一个注意力头根据这两个信息选择正确的收尾引号。
整条回路只用到了12个节点和9条边(12 nodes and 9 edges)。模型不是“凭感觉”补引号,它真的会先判断引号种类,再选择对应闭合符号。
研究人员还模拟了删除节点的情况。这条回路足够让模型完成任务,就算他们通过均值消融——将目标节点的激活固定为预训练分布的均值,模拟节点失效——移除模型的其他部分,只保留这个回路,模型也能完成补全引号的任务;反过来,消融目标节点,保留模型的其余部分,也会导致模型完不成这项任务。
这说明他们的发现并非巧合,而是模型切实的工作机制,是模型内部机制可解释性上的突破。
高昂代价
通过进一步实验,研究团队发现,对于固定大小的模型,似乎模型的可解释性和能力只能此消彼长。模型中固定为零的参数越多,模型的性能越差,但模型的可解释性会越高。如果想同时提高模型的细腻功能和可解释性,只能不断扩大模型的总参数量——AI的扩展定律(scaling law)在这里再次显现了。
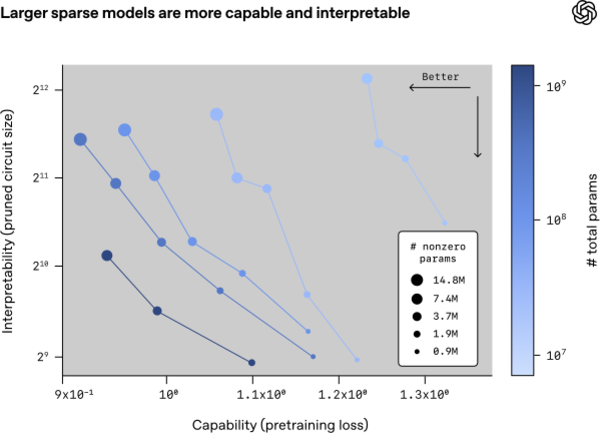
横轴为模型的性能,越靠左越好;纵轴为模型的可解释性,越靠下越好。数据点的颜色代表模型的总参数量,颜色越深代表总参数量越大;数据点的大小表示模型中非零参数的数量,点越大表示非零参数越多。对于总参数量相同的模型,模型中非零参数越多,性能越强,可解释性越差;非零参数越少,性能越差,可解释性越强。要想同时提升模型的性能和可解释性(靠左下),需要提升模型的总参数规模。图片来源:OpenAI
我们终于在模型内部机制的可解释性上迈出了关键的一步,并且找到了模型性能和稀疏性之间的规律。似乎终于有办法提升模型的可解释性了。
但代价是什么呢?
代价是训练成本。稀疏训练的速度非常慢,需要付出100~1000倍的成本。而且,就算如此,本次OpenAI的论文也不敢断言他们完全理解了GPT-2内部的运行机制。
而在GPT-2之后,还有175B的GPT-3,万亿级参数的GPT-4,甚至更大的GPT-5。如果真的想用这种方法来解释后续模型的运行机制,恐怕人类目前还付不起如此高昂的算力成本。
今年11月,Ilya Sutskever(OpenAI联合创始人,现已离职创立Safe Superintelligence公司)在采访中表示AI的扩展时代(age of scaling)已经终结了,我们正在重回模型的研究时代(Age of Research)。人类创造的预训练数据几乎耗尽,扩展模型规模的回报也在边际递减。我们需要寻找新的配方,更聪明地使用有限的算力。
大模型依然重要,我们已经离不开大模型了。但想让它高效地接管更多数据,我们对模型运行机制的理解,似乎正在显得愈发重要。
参考链接:https://openai.com/index/understanding-neural-networks-through-sparse-circuits/
https://arxiv.org/pdf/2303.12712
https://wallstreetcn.com/articles/3760137